

CAMEL DatabaseAgent: 将复杂数据查询转化为自然对话的开源解决方案
数据分析的痛点与解决方案
在当今数据驱动的企业环境中,一个常见场景是:业务分析师急需某项数据分析,但必须等待懂SQL的技术团队成员提供支持。根据McKinsey的一项研究,分析师平均花费30-40%的时间仅用于数据准备和查询构建。这种依赖不仅延迟决策过程,还增加了技术团队的工作负担。
这就是为什么我开发了CAMEL DatabaseAgent — 一个革命性的开源工具,它能够让任何人通过自然语言与数据库对话,就像与同事交流一样简单。无需编写一行SQL代码,分析师可以直接获取他们需要的数据洞察。
CAMEL DatabaseAgent的核心优势
相比市场上其他文本到SQL工具,CAMEL DatabaseAgent具有以下显著优势:
- 完全开源:透明的代码和社区驱动的开发确保了持续改进和定制灵活性
- 多语言支持:能够理解和响应包括中文、英文、韩文在内的多种语言查询
- 自动数据库理解:分析数据库结构并生成适当的少样本学习示例
- 只读模式:默认安全操作,保护数据库不被意外修改
- 简单集成:易于与现有系统和工作流程集成
技术架构:它是如何工作的
CAMEL DatabaseAgent建立在CAMEL-AI之上,由三个核心组件构成:
DataQueryInferencePipeline:这个智能组件分析你的数据库结构并自动生成训练示例,包括问题和对应的SQL查询。它使用了先进的推理技术来理解表之间的关系和数据的语义。
DatabaseKnowledge:一个专门设计的向量数据库,用于高效存储和检索数据库模式、样本数据和查询模式。这个组件使系统能够快速"回忆"相关的数据库知识来回答用户问题。
DatabaseAgent:基于大语言模型(LLM)的智能代理,它接收自然语言问题,利用DatabaseKnowledge生成精确的SQL查询,执行查询,并以用户友好的格式返回结果。
支持的数据库系统包括:
- SQLite
- MySQL
- PostgreSQL
所有操作默认在只读模式下进行,确保数据安全。
实际应用案例:从简单到复杂
我在一个音乐分发平台的真实数据库上测试了这个工具,结果令人印象深刻。以下是按复杂度递增的几个应用场景:
基础查询
当我问"查找包含超过10首曲目的播放列表名称"时,系统立即生成了正确的SQL:
 系统能够理解简单的筛选和计数需求
系统能够理解简单的筛选和计数需求
中等复杂度查询
场景一: 统计特定时间段内的销售数据
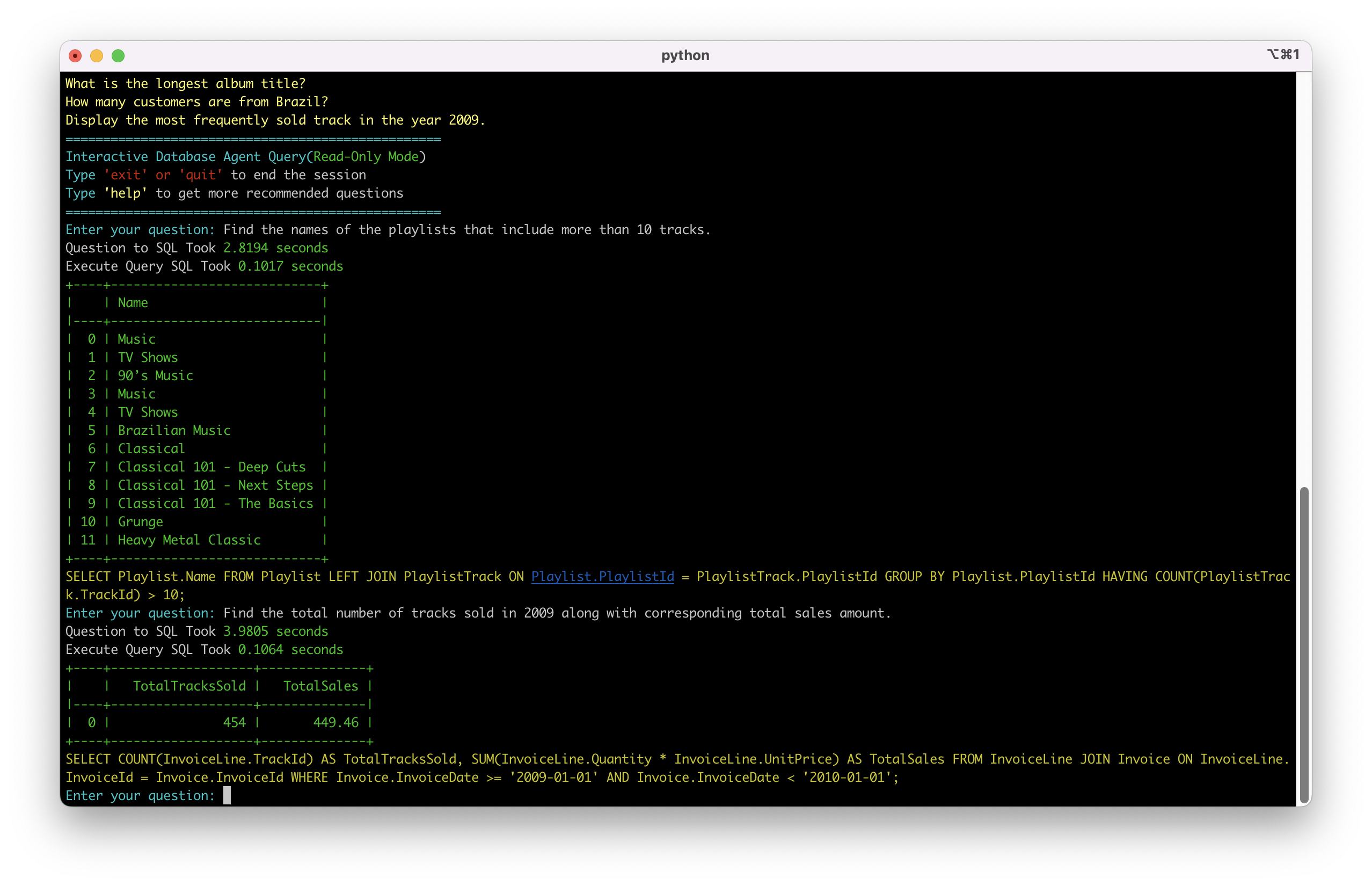 系统成功处理了多表连接和时间范围筛选
系统成功处理了多表连接和时间范围筛选
场景二: 按类别分组的财务分析
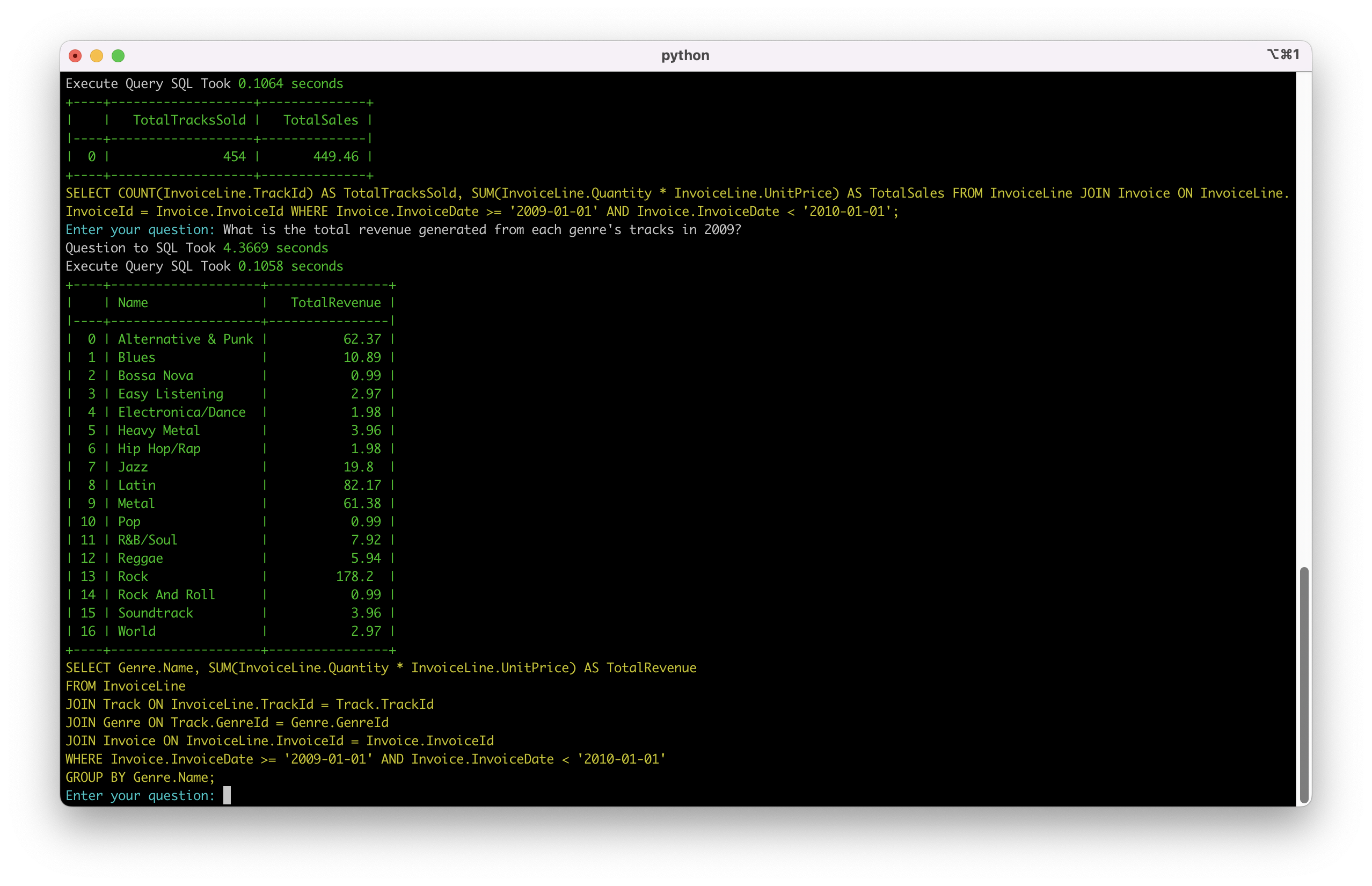 系统能够理解分组、聚合和复杂的表关系
系统能够理解分组、聚合和复杂的表关系
高级分析查询
场景三: 性能排名分析
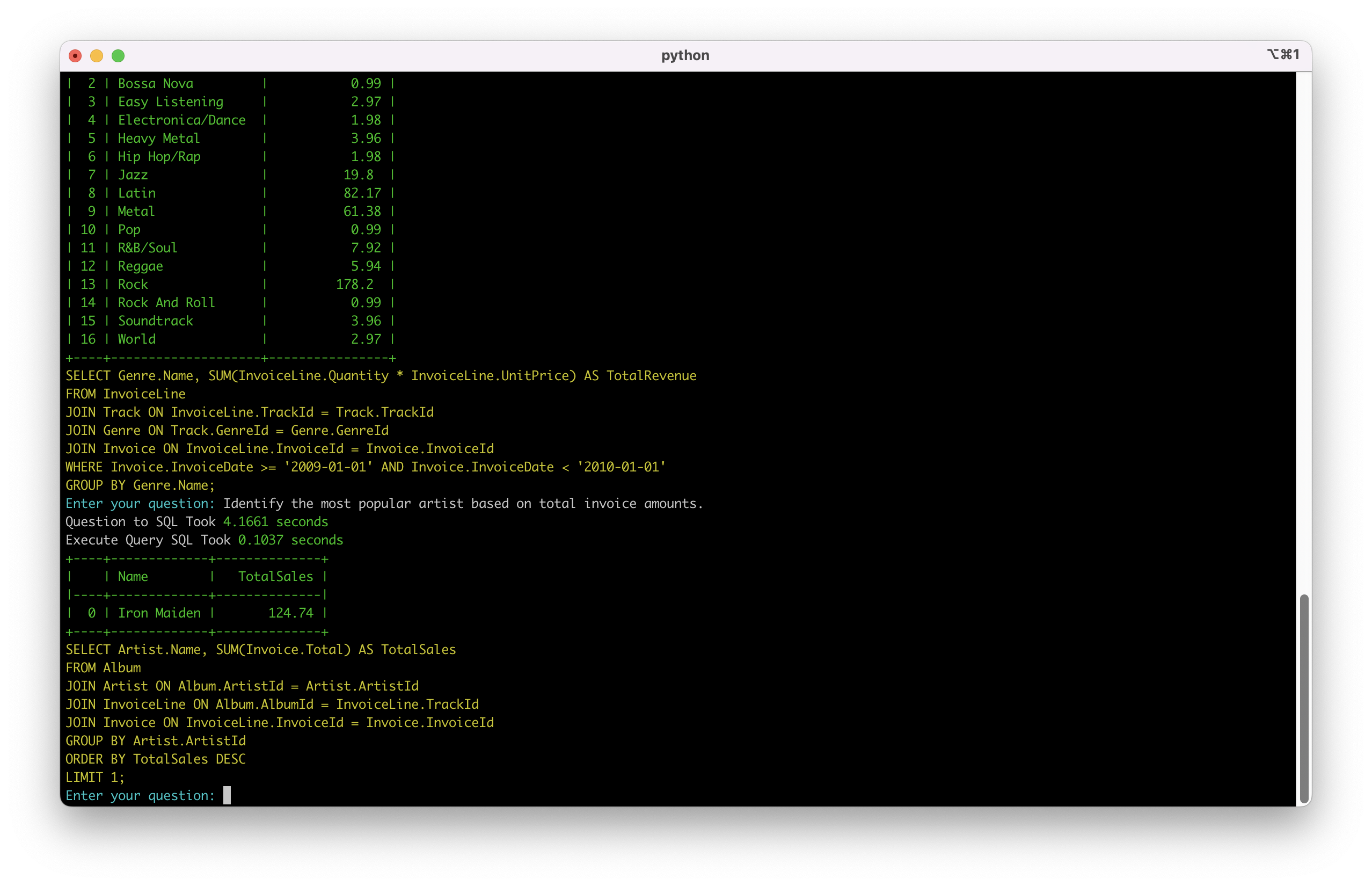 系统处理了多表连接、排序和限制条件
系统处理了多表连接、排序和限制条件
场景四: 条件筛选和计数
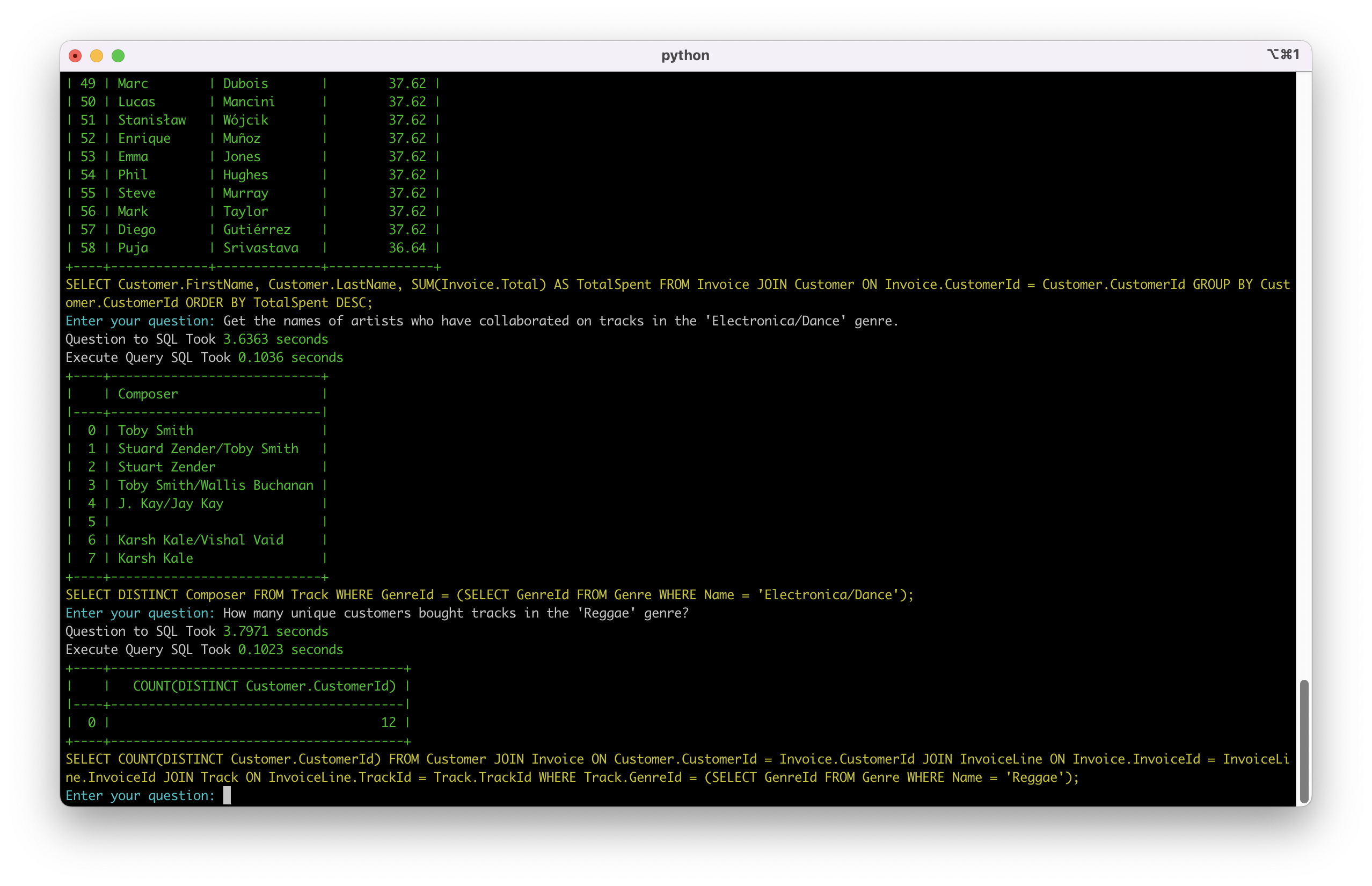 系统能够使用子查询和复杂条件
系统能够使用子查询和复杂条件
场景五: 百分比计算
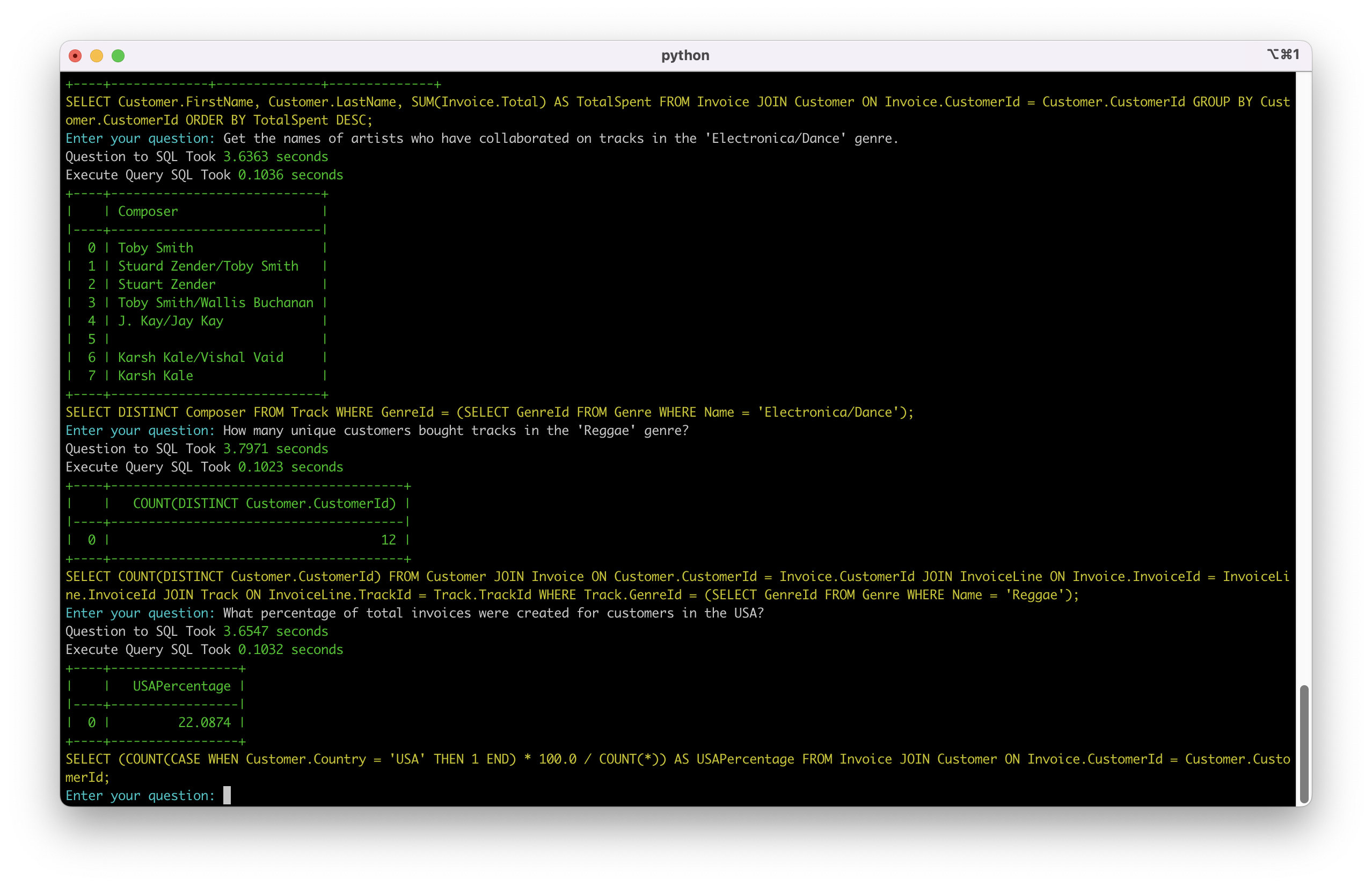 系统能够执行数学计算和条件计数
系统能够执行数学计算和条件计数
场景六: 复杂关联分析
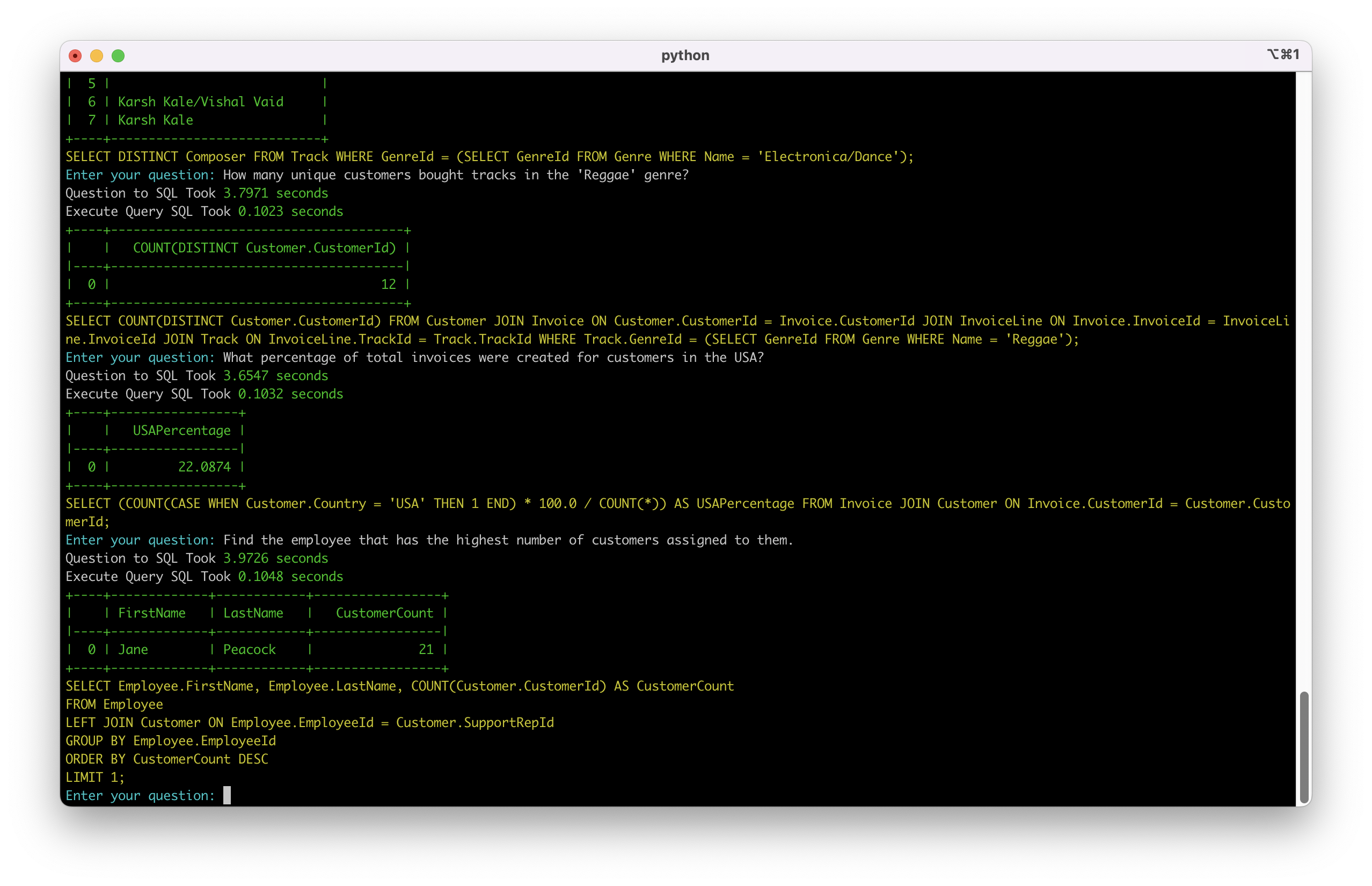 系统能处理左连接和空值情况
系统能处理左连接和空值情况
突破语言障碍:多语言支持
在全球化团队环境中,语言障碍常常是数据协作的瓶颈。CAMEL DatabaseAgent支持多语言交互,让来自不同语言背景的团队成员都能使用自己的母语训练知识并进行数据查询。
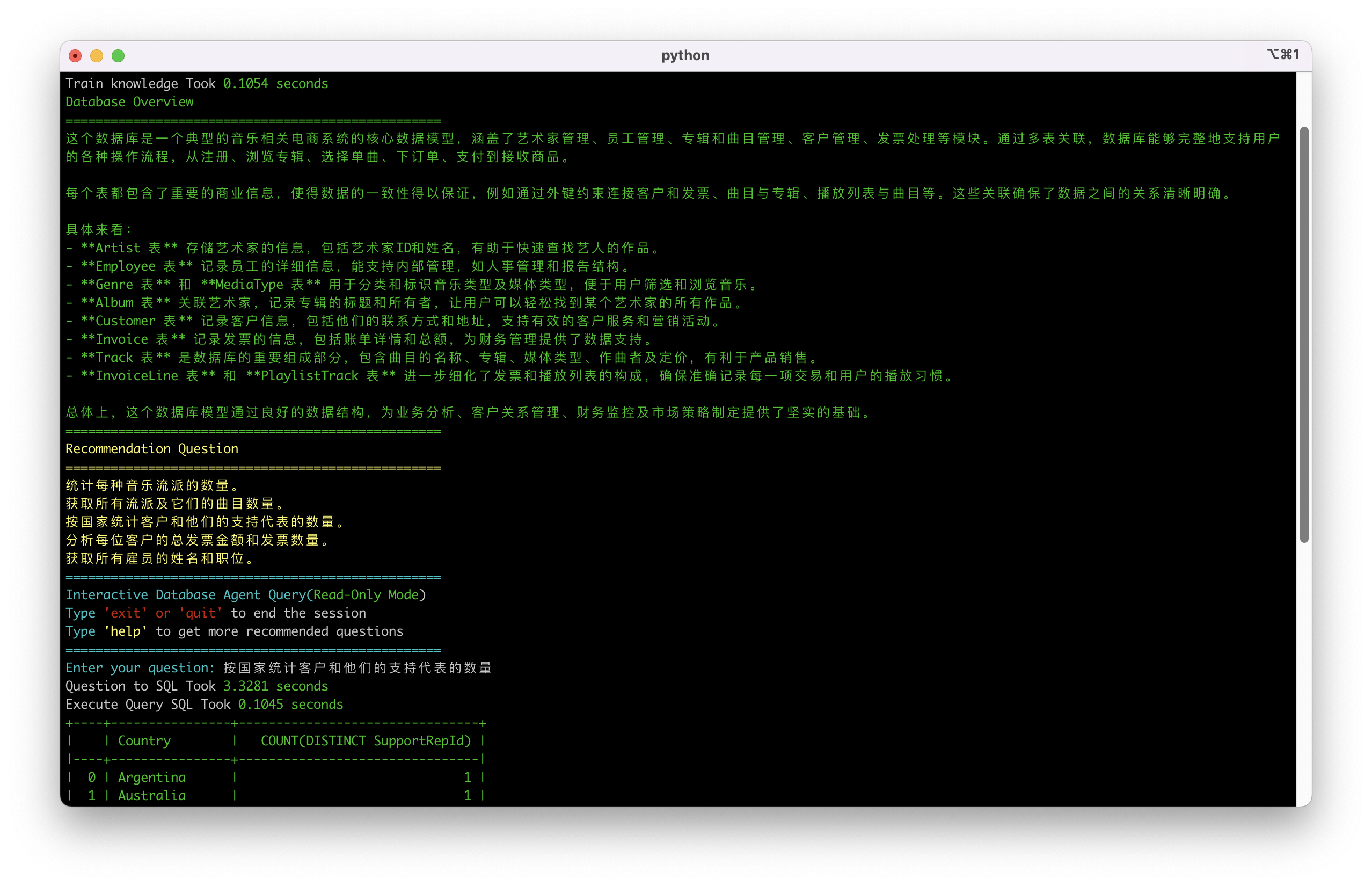 使用中文训练知识并提问
使用中文训练知识并提问
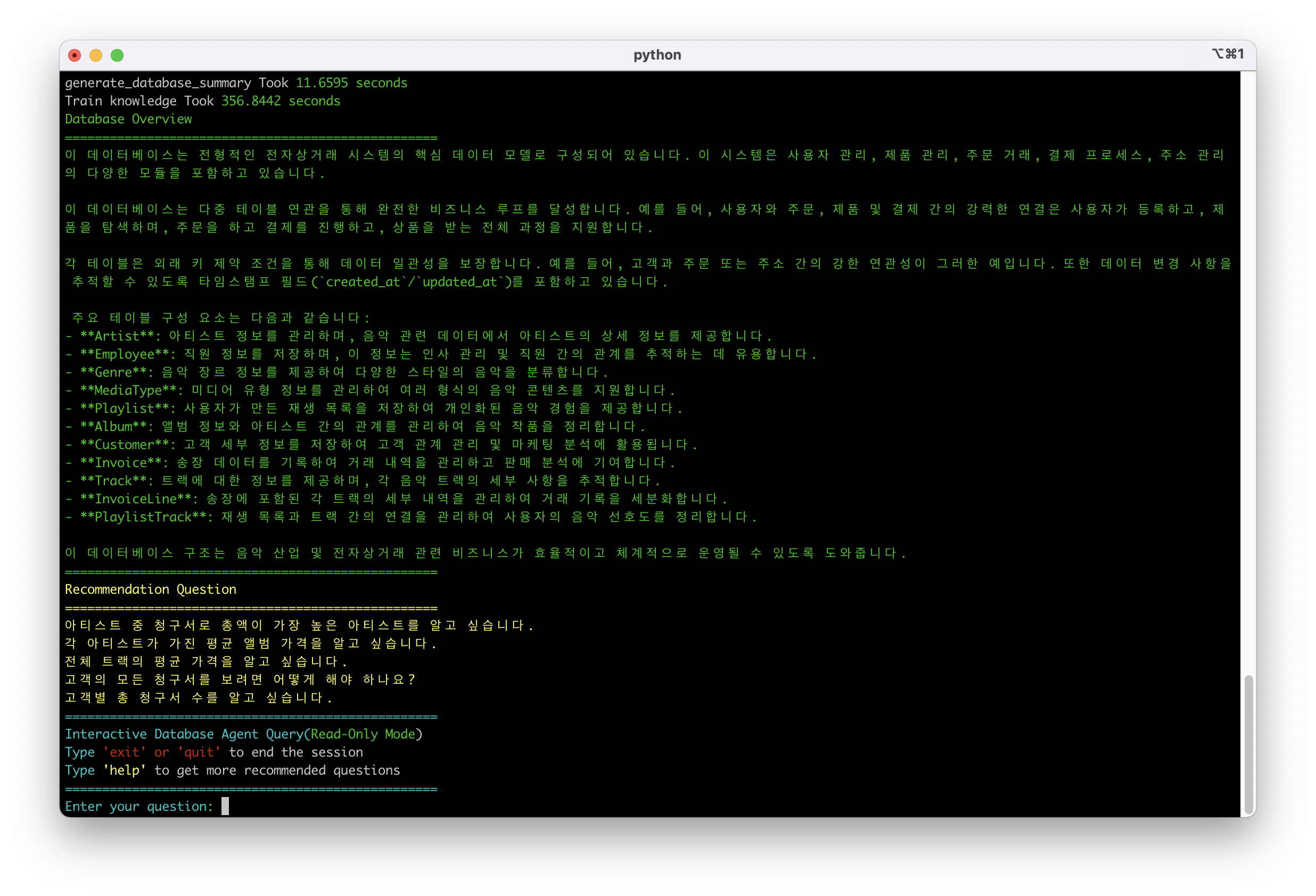 系统同样支持韩文等其他语言,而你要做的只是在连接数据库的时候指定语言
系统同样支持韩文等其他语言,而你要做的只是在连接数据库的时候指定语言
入门指南:5分钟上手
想要尝试CAMEL DatabaseAgent?只需几个简单步骤:
# 1. 克隆仓库
git clone git@github.com:coolbeevip/camel-database-agent.git
cd camel-database-agent
# 2. 设置环境
pip install uv ruff mypy
uv venv .venv --python=3.10
source .venv/bin/activate
uv sync --all-extras
# 3. 配置API密钥
export OPENAI_API_KEY=sk-xxx
export OPENAI_API_BASE_URL=https://api.openai.com/v1/
export MODEL_NAME=gpt-4o-mini
# 4. 连接到示例数据库并开始使用
python camel_database_agent/cli.py \
--database-url sqlite:///database/sqlite/music.sqlite
首次连接时,系统会花几分钟分析数据库并生成知识库。之后的使用将非常流畅,响应时间通常在1-3秒内。
为开发者提供的集成API
对于希望在自己的应用或系统中集成此功能的开发者,我们提供了简洁的Python API:
# 安装依赖库
pip install camel-database-agent
# 初始化数据库代理
from camel_database_agent import DatabaseAgent, DatabaseManager, TrainLevel
from camel_database_agent.models import ModelFactory, OpenAIEmbedding
import uuid
database_agent = DatabaseAgent(
interactive_mode=True,
database_manager=DatabaseManager(db_url=database_url),
model=ModelFactory.create(
provider="openai",
model_name="gpt-4o-mini"
),
embedding_model=OpenAIEmbedding()
)
# 训练代理对数据库模式的知识
database_agent.train_knowledge(level=TrainLevel.MEDIUM)
# 使用自然语言执行查询
response = database_agent.ask(
session_id=str(uuid.uuid4()),
question="列出所有包含超过5首曲目的播放列表"
)
# 处理返回的结果
print(response.answer) # 自然语言回答
print(response.sql) # 生成的SQL查询
print(response.data) # 结构化的查询结果
结语
CAMEL DatabaseAgent代表了数据库交互的未来——使数据查询变得像日常对话一样自然。它不仅提高了数据分析师的工作效率,还赋予了非技术人员直接获取数据洞察的能力,从而加速整个组织的决策过程。
在数据民主化的时代,工具不应该成为获取洞察的障碍。通过CAMEL DatabaseAgent,我希望为打破这些障碍做出贡献,让每个人都能轻松与数据对话。
GitHub链接:https://github.com/coolbeevip/camel-database-agent
如果你觉得这个项目有价值,别忘了给它点个星⭐!你的支持是开源项目发展的动力!