

具身智能大脑负责什么:一个场景化边界分析
导读
本文只讨论一个问题:把具身智能系统拆开以后,具身智能大脑到底负责哪一段。
这个问题不能靠抽象定义回答,只能放进具体场景里看。下面用一个动态非结构化实验室危险品二次分类场景,把执行层、空间智能、世界模型、具身智能大脑的边界拆开。
先把几个词说清楚,后面会轻松很多:
SO101:一种低成本桌面机械臂,这里把它当作具身平台的代表空间智能:负责理解几何关系、障碍物和局部物理安全的层世界模型:用于估计动作发生后环境可能如何演化的预测模型具身智能大脑:负责处理意图、风险和重规划的治理层
| 层级 | 职责 |
|---|---|
| 执行层 | 把指令转成电机和关节级控制 |
| 空间智能 | 识别几何关系并维持即时安全 |
| 世界模型 | 预测接下来可能发生什么 |
| 具身智能大脑 | 重建执行计划并做治理性决策 |
场景设定:动态非结构化环境下的实验室危险品二次分类
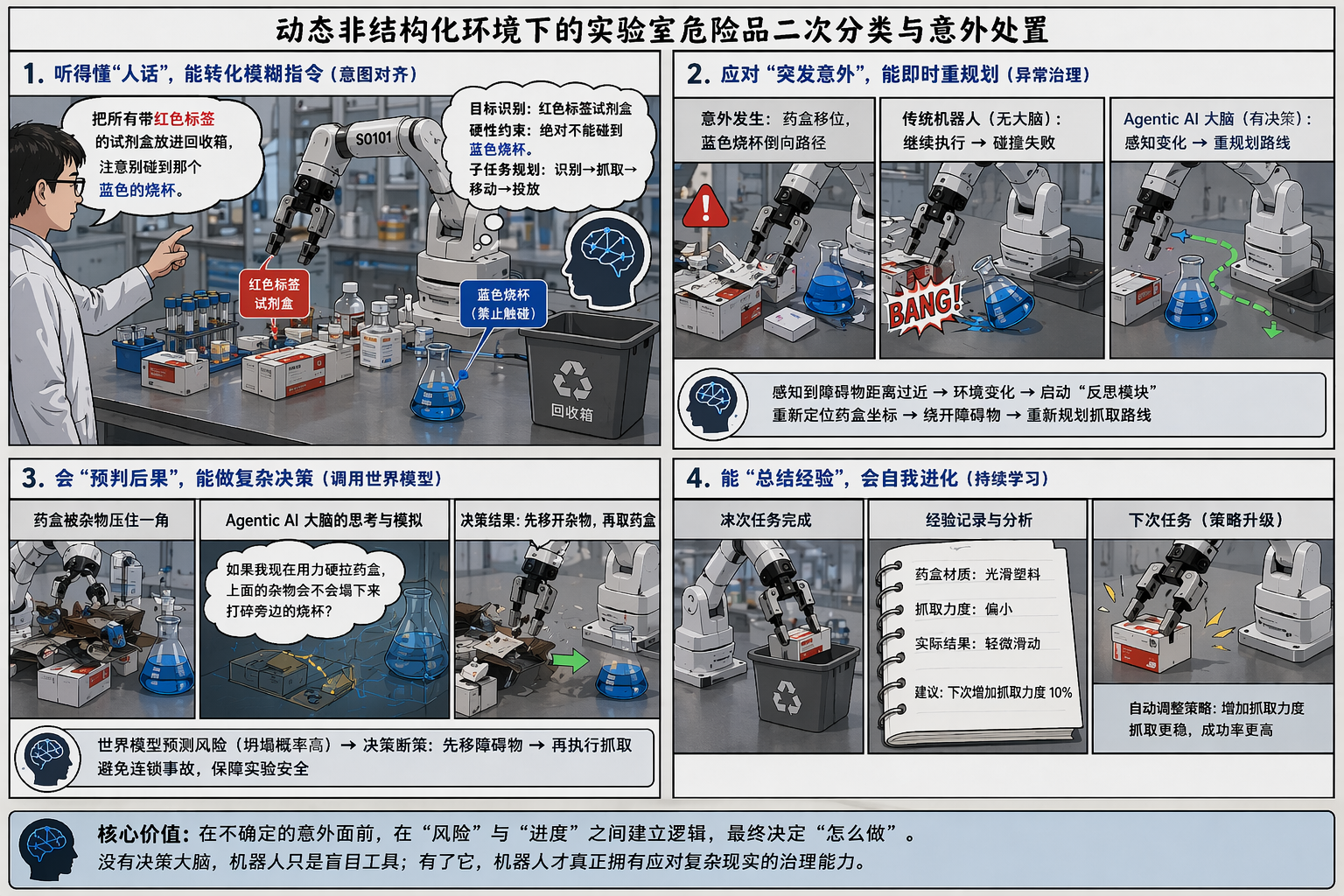
这里选一个适合 SO101 这类低成本机械臂平台的任务作为分析基准:
动态非结构化环境下的实验室危险品二次分类与意外处置。
选这个场景,有三个现实前提。
第一,没有昂贵的机械臂本体。分析对象不是高自由度、高精度的工业级平台,而是类似 SO101 这样的低成本机械臂。所以讨论重点不能压在本体性能上,只能压在系统层的任务组织、异常治理和风险控制上。
第二,搭不起复杂实验环境。没有高规格实验室,没有大规模传感器阵列,也没有完整的工业安全隔离设施。场景必须能在有限的桌面环境里复现,同时还能把任务目标、环境扰动和安全约束之间的冲突暴露出来。
第三,场景本身得能说明问题。它不能只是一个静态抓取 demo,不然看到最后还是感知和轨迹执行,执行层、空间智能、世界模型、具身智能大脑的边界都拉不开。实验室危险品二次分类这个任务同时带着语义目标、动态扰动和风险后果,正好能把系统真正要回答的问题逼出来。
这个场景同时带着三类复杂性:
- 指令是模糊的,需要做语义对齐
- 环境是动态的,执行中会发生突变
- 决策带有安全后果,不能只追求动作完成
用它来检验这四层的边界,够用了。
边界零:执行层负责驱动机械臂,不负责理解任务
这里的执行层包括运动控制、轨迹跟踪、伺服驱动、夹爪开合、关节级控制和底层安全联锁。它接收上层给出的目标位姿、轨迹段、速度约束、抓取力度或停止指令,再把这些东西变成电机、关节和末端执行器真正能执行的控制信号。
执行层的职责包括:
- 将目标位姿或轨迹转换为关节级控制命令
- 保证轨迹跟踪、速度控制和夹爪执行
- 在控制周期内维持伺服稳定性和执行精度
- 响应急停、限位、力控阈值等底层保护机制
这一层管的是动作怎么稳定、可重复地落到机械臂上。
边界一:具身智能大脑处理意图,不直接下沉到动作控制
先看任务输入。
把桌面上所有带红色标签的试剂盒放进回收箱,不要碰到那个蓝色烧杯。
这句话看上去很简单,但里面已经埋了很多约束:
- “所有带红色标签的试剂盒"不是一个固定坐标,而是一类语义目标
- “放进回收箱"不是单步动作,而是一串子任务
- “不要碰到蓝色烧杯"不是建议,而是一个硬约束
这里关键不是动作序列,而是执行计划。
这一阶段,具身智能大脑负责意图对齐:
- 识别用户到底想处理什么对象
- 明确哪些对象是可操作目标
- 明确哪些对象是绝对不能碰的约束物
- 把自然语言指令拆成可执行的子目标链
把模糊的人类目标,整理成带约束的执行计划。
边界二:空间智能看几何变化,具身智能大脑重建执行计划
再看一个执行中断事件。
SO101 正在抓取一盒带红色标签的试剂盒,实验室工作人员意外碰撞了桌面。结果有两个变化同时发生:
- 药盒相对原位置偏移了大约 5 厘米
- 蓝色烧杯朝机械臂原有运动路径方向倾斜
空间智能负责什么
空间智能负责对几何变化做快速感知和即时响应。
它看到的是:
- 目标位置变了
- 障碍物姿态变了
- 原路径的碰撞风险变高了
它先保物理安全闭环。
这一层要做的事很直接:
- 快速检测空间几何变化
- 触发避障机制
- 必要时通过控制障碍函数或其他安全控制逻辑强制停机
把这一层看成具身系统的 System 1 也没问题。它反应快,闭环硬,先把事故拦住。
具身智能大脑在这里做什么
System 1 刹住之后,具身智能大脑才真正接管。
这时要处理的已经不是“目标坐标变了没有”,而是原来的执行计划还算不算数。
例子:机械臂在物理上仍然能够到达那个盒子,问题是原来的执行计划已经失效了:“抓取这个物体,但不要碰到蓝色烧杯。” 到达仍然可能,继续执行已经失去正当性。
少了这一层,机械臂最常见的错误就是沿着旧计划继续跑。
Hallucination in Action。
动作层还在执行,只是执行前提已经失效了。
所以它的第二个职责是:
环境和计划脱节之后,停掉旧计划,重新建一个能执行的新计划。
边界三:世界模型推演后果,具身智能大脑做策略取舍
再往场景里加一点约束,让它更像真实实验室。
那盒试剂盒虽然还能看到,但它的一角被其他杂物压住了。
于是问题变成:
机械臂如果现在直接抓,会不会把上面的杂物带倒?如果倒了,会不会砸到旁边的烧杯?如果烧杯被碰翻,风险是不是已经超过了当前任务收益?
这里要回答的是物理后果。具身智能大脑能组织决策,但它不是物理仿真器。
世界模型负责什么
世界模型擅长回答这样的问题:
如果我执行某个动作,接下来物理世界更可能如何演化?
比如在这个场景里,它适合回答:
- 如果以当前力度强行拉动药盒,杂物坍塌概率多大?
- 如果先抬起再侧拉,烧杯受扰动风险如何变化?
- 哪种动作序列更容易引发连锁碰撞?
它负责后果预测。
为什么世界模型替不了具身智能大脑
即使世界模型给出了坍塌概率,最后还是得有人决定下一步怎么做:
- 是继续执行,还是放弃当前动作?
- 是先移开杂物,还是重新选目标?
- 是优先保证安全,还是继续追求任务进度?
所以它的第三个职责是:
调用世界模型,吸收后果预测,再把预测结果变成策略选择。
用同一场景验证五个执行阶段
把这个框架映射回任务执行链,可以得到五个连续阶段。
阶段一:语义对齐与执行计划生成
用户下达高层指令:
把所有带红色标签的试剂盒放进回收箱,注意别碰到那个蓝色烧杯。
具身智能大脑先做语义对齐:
- 识别红色标签试剂盒是任务目标
- 识别蓝色烧杯是禁止触碰的硬约束
- 生成"识别 -> 抓取 -> 搬运 -> 投放"的子任务链
阶段二:异常触发后的几何制动与执行计划重建
执行中桌面被意外碰撞,药盒偏移,烧杯倾斜。
空间智能先快速响应:
- 感知几何变化
- 停止原运动路径
- 避免立即撞击
随后具身智能大脑接管:
- 中止旧计划
- 重定位目标和约束
- 生成新的抓取路径
阶段三:后果预测驱动的策略选择
药盒被杂物压住,不能直接粗暴抓取。
此时具身智能大脑发起对世界模型的查询:
- 如果强行拉动,会不会带倒上层杂物?
- 杂物坍塌后会不会打碎烧杯?
世界模型给出后果概率,具身智能大脑据此做决策:
- 放弃直接拉动
- 改成先移开障碍物
- 再重新执行抓取
阶段四:执行层完成轨迹跟踪与末端执行
具身智能大脑完成策略选择、空间智能补上局部安全约束之后,动作真正落到机械臂上,就归执行层。
执行层在这一阶段负责:
- 按目标位姿和轨迹段驱动关节运动
- 控制夹爪张开、闭合和抓取力度
- 在执行过程中维持轨迹跟踪误差、速度约束和伺服稳定性
- 在收到上层中断信号时立即停机或切换控制模式
没有这一层,前面的判断都落不到机械臂上。
阶段五:经验回灌与策略更新
任务结束后,系统还会把这次经验记下来:
- 药盒包装材质偏滑
- 初始抓取力偏小
- 首次策略不够稳健
下次再遇到同类材质时,系统会在规划阶段主动提高抓取力度或调整抓取策略。
这也说明具身智能大脑不只是一次性出计划,它还负责把经验回灌到治理层。
失败责任归属图
把这四层边界放到工程现场,最有用的地方不在定义本身,而在于出问题时能很快判断责任落在哪一层。
| 失败现象 | 责任层 |
|---|---|
| 障碍物位置变化后机器人发生碰撞 | 空间智能 |
| 机器人继续沿用已经过时的目标 | 具身智能大脑 |
| 系统低估了坍塌风险 | 世界模型 |
| 机器人无法跟踪既定轨迹 | 执行层 |
这张表可以直接拿来做两件事:
- 分工:明确每一层该解决什么类型的问题
- 排障:系统失败后先判断责任层,再往下查实现细节
结论
执行层决定怎么动,空间智能决定眼前什么是安全的,具身智能大脑决定系统是否还应该继续行动。
具身智能大脑的真正作用,不是让机器人显得更聪明,而是让整个系统对自己的行为负责。